Integrate your legacy applications with JNI
Learn how to integrate a legacy accounting application and a new sales force automation program using JNI
IT professionals must often marry old and new technologies, a challenge requiring the technical knowledge to evaluate which tools are best for a particular project. In this article, I will show you how to integrate a legacy accounting application (which we will call Beetle) and a new sales force automation program (Aphid), using Java Native Interface (JNI) as our tool of choice.
Beetle is a double-entry accounting system that tracks A/R, A/P, and payroll. Sales representatives use Aphid to track their calls, appointments, and sales by account. In accounting, the term double entry means that a credit is balanced by a debit and vice versa, so Beetle’s double-entry system ensures that balance is achieved.
In application development, however, double entry means that the same information is manually entered twice, usually on two separate systems. That is not only inefficient but also a basis for human error; our goal is to eliminate that form of double entry by integrating Aphid and Beetle. When a sales representative completes a sale, Aphid will enter the invoice into Beetle, along with the representative’s 5 percent commission. To help motivate our sales force, Aphid will display all the representative’s commissions, with payment status extracted from Beetle.
Assess the technology
The first step in our development project is to determine the appropriate technology for the job. Because platform, connectivity, and storage decisions are usually predetermined, often mandated from above, our best bet is to use a software model that can perform independent of, or at least very loosely dependent on, the technology. When it comes to legacy applications, we don’t have too many options: Beetle was already written in C, using ODBC to manipulate an Access database. A secondary consideration is a movement elsewhere in the company to migrate to Oracle, but that’s a decision over which we have no control right now.
In this case, using Java makes the most sense. Because we need to integrate with a C application, C++ might appear an attractive choice at first glance. But the sales representatives travel quite frequently, and they need access, either disconnected or dialed-in from a hotel room, to the application from their laptops. For Aphid, we want to take advantage of Java’s power on both the server and the client, and use XML for storage and transmission; the need for an XML-based disconnected client/server solution dictates Java as our tool of choice. When choosing a technology, remember to weigh all the project’s requirements and not let one specific detail — such as C integration — force us into a particular implementation.
Fortunately, Java Native Interface gives us the flexibility that we require. JNI was developed as a way for Java applications to take advantage of platform-native resources; it allows the JVM to interoperate with applications and libraries written in C, C++, assembly, and several other languages. With JNI, not only can Java call native code but the native code can also create and manipulate Java objects. The result is that JNI allows full language interoperability, making it an ideal candidate for legacy application integration.
To integrate Aphid with Beetle, we could have chosen to access the database directly through JDBC, which would have yielded disastrous consequences. Because much of the business logic that is necessary for proper operation (such as balance-based double entry) is actually encoded within Beetle, circumventing the application would require us to duplicate the business logic in Aphid.
Moreover, the possibility of an Oracle migration means that we can’t be sure of the future database schema, and much of the business logic could eventually be pushed down into stored procedures. Coding Aphid directly to the database opens it up to maintenance problems down the road. Going through the JNI interface, though, localizes future changes and isolates Aphid from significant maintenance concerns.
Model the information
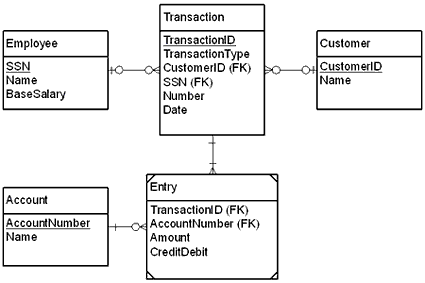
Once we have decided upon the technology, the next step is to create the information model, otherwise known as the software model. Beetle is based on a relational database, so we can simply extract the entity relationship diagram in Figure 1. The most important tables are Transaction and Entry. Each transaction consists of two or more entries, each a credit or debit to a particular account. The total credits for any given transaction must equal the total debits, and Beetle’s C code ensures that balance is always met.

Because Aphid is written in an object-oriented language, its information model is most easily expressed in UML. The model for Aphid appears in the left side of Figure 2. UML’s diamond notation denotes ownership instead of aggregation — ownership is a more rigorous relationship than aggregation, as each object (except a singleton) has exactly one owner. In Aphid, the Company singleton owns everything else.

To illustrate the relationship between the two applications, the important pieces of the Beetle ERD are translated into UML on the right side of Figure 2. To fulfill the rule of ownership, the Beetle model also includes a Company singleton. (As we will see when we start coding, that extra object will come in quite handy.) Then we map the Aphid objects to their corresponding Beetle objects: a representative is an employee of the company, an account is the rep’s term for a customer, and a sale generates both an invoice and a commission.
Aphid has its own information model, separate from — but connected to — the Beetle information model. Aphid will need its own storage mechanism as well. We’ve already decided to use XML for storage, but we still need to figure out how to join Aphid’s XML document to Beetle’s relational database. Beetle must share a secret about each object in which Aphid is interested, so that Aphid can persist the connection and request the object the next time it is needed. Beetle must share each record’s key and, to avoid excessive dependence on Beetle’s database schema, Aphid will treat all keys as text strings, or cookies. Aphid will retrieve its cookies from Beetle, return its cookies to Beetle, and make no further assumptions about the information.
Set up the environment
Now that we have the technology assessment and information models in place, we can assemble our development environment. (See Resources to download sample code.) Please note that the attached sample code does not implement Aphid’s client/server behavior, its disconnected operation, or its XML transactions. In the sample, both the Aphid GUI and Beetle UI run on the same machine, which would not hold true in actual production.
We now identify four target modules. Both applications run independently, so they are represented as top-level modules, AphidApp.class and BeetleUI.exe. To access the native code from a standalone Java program, JNI loads a DLL, and the Beetle business logic is extracted to a separate module, BeetleBL.dll. To localize the JNI support, we create a wrapper module, BeetleJNI.dll. The module relationship diagram appears in Figure 3. Notice that only the Beetle business logic module has direct access to the database.

Because Beetle was originally written in C, we will use C for both BeetleUI.exe and BeetleBL.dll. However, JNI code is slightly more readable when written in C++, so we will use C++ for BeetleJNI.dll. (I used Microsoft Visual C++ 6.0 and Borland JBuilder Foundation 3.5 to create those modules, though I attempted to avoid anything compiler-specific. You will need a C/C++ compiler, a Java 1.2.2 compiler and VM, and ODBC. Create an ODBC data source named BEETLE, which references the database “Beetle.mdb” included in the sample source code.)
Since we are starting with a legacy application, we already have a module called Beetle.exe. First, we want to rename that project BeetleUI.exe to reflect the new separation of user interface from business logic, and then we want to create empty projects for each of the other modules. We design a directory structure that separates C code from Java code, Java source files from Java class files, and the various C modules from the database (please see sample code).
One important consideration when developing a JNI project is that JNI searches for native modules within CLASSPATH. Therefore, we must create a separate directory called devpath for all the C modules and put it in our PATH environment variable. We then instruct the C/C++ compiler to write all output files into devpath. A quick reboot makes the new PATH take effect, and now we are ready to code.
Connect the modules
First, to instruct JNI to load our new module, we must place a call to the static function System.loadLibrary in an appropriate place. Because the class Beetle.Company is the top of the JNI-specific code, putting the call in its static initializer makes sense. The code is as follows:
public class Company {
...
static {
System.loadLibrary("BeetleJNI");
}
...
}
The Java runtime searches for BeetleJNI.dll in CLASSPATH and automatically matches up all native methods. But wait — we haven’t written any native methods.
Once again, from the beginning: When a sales representative starts Aphid, the Aphid.Representative object must request the Beetle.Employee object to which it is connected. All it has is a cookie. Because Beetle.Company is the owner of Beetle.Employee, Aphid.Representative passes the cookie to Beetle.Company. Beetle.Company must access the business logic layer to complete the request, so that is where we require our first native method. The code on the Java side looks like this:
native private Employee loadEmployee( long nEmployeeSS );
Of course, we want to hide the fact that the cookie is really the employee’s social security number encoded as a long integer from Aphid. We make the method private so that Aphid.Representative can’t call it directly — it has to go through the public method Employee lookupEmployee( String cookie ).
Notice that the Java method does not include an implementation; the implementation appears in the C++ module BeetleJNI.dll. The function must be declared precisely as follows so that JNI can match it to the proper native method declaration:
extern "C"
{
_BEETLEJNI_EXPORT_ jobject JNICALL Java_Beetle_Company_loadEmployee(
JNIEnv *env,
jobject obj,
jlong nEmployeeSSN);
}
A little explanation is in order here: The function name identifies itself as JNI native code (Java_) and identifies the package (Beetle_), class (Company_), and method (loadEmployee). It takes a JNI environment object (JNIEnv *env) (which we will use to communicate with the VM), a reference to the Company instance (jobject obj), and the long parameter that we declared in Java (jlong nEmployeeSSN). Because we declared that the native method returns an Employee object in Java, the C++ function returns jobject. The extern "C" and JNICALL modifiers ensure that the name is not mangled and that the proper calling convention is used. And of course, _BEETLEJNI_EXPORT_ is a macro that instructs the compiler to export the function from the DLL. (See Sidebar 1 for more information about native method naming.)
To make sure that everything is working properly thus far, we create an empty stub for the native code — just enough to hold a breakpoint. Then we implement the Java code to invoke our native method. (Calling a native method in Java is exactly the same as calling a Java method.) We set up the debugger to run BeetleJNI.dll by way of Aphid. In Visual C++, that can be accomplished in the Debug panel of the Project Settings dialog by specifying “D:JBuilder35jdk1.2.2binjavaw.exe” as the “Executable for debug session” and “-classpath D:DevLaijniJavaclasses Aphid.App” as the program arguments. (I have the JDK installed in “D:JBuilder35jdk1.2.2” and the source code starting in “D:DevLaijni”; your configuration may differ.) We can then set the breakpoint and run the program, and we shouldn’t continue until the breakpoint is hit, confirming that we have correctly connected the modules.
Break out the code
With our framework firmly in place, we can start hanging code from the rafters. We must complete the first native method before moving on to the next, which requires that we modify code in all four modules on each iteration. That sequential movement also allows us to compile and test a stable build before moving on to the next change. The new development in Aphid and BeetleJNI.dll is not the risky part — it’s the legacy code that’s perilous ground.
The separation of the Beetle business logic from its user interface is the most difficult undertaking in our dev project. Beetle was originally developed as a single standalone application, and calling across module boundaries is not as trivial as calling within one module. The best advice is to take it slow, and don’t try to rip out all the business logic at once. Instead, factor out small chunks as you need them, recompiling and testing everything at each step.
Making use of a good configuration management tool at this point is crucial; check everything in after each successful test, and don’t be afraid to go back to the last stable build if it’s not working. Ideally, business logic should function independently of user interface, but if you find that the business logic makes calls back to the user interface, you may have to use C function pointers or C++ abstract base classes to make the DLL call the EXE. (Such techniques, while not terribly difficult, are beyond the scope of this article.)
To complete the first native method, we must break out the business logic that loads an Employee record from the database. We put that into a function in BeetleBL.dll called LoadEmployee, which takes the social security number and returns the name and a success code. Our native method calls that new business logic function, constructs a new Employee object, and maps the new object to its key so that it won’t have to be loaded again. The code appears below:
_BEETLEJNI_EXPORT_ jobject JNICALL Java_Beetle_Company_loadEmployee(
JNIEnv *env,
jobject obj,
jlong nEmployeeSSN)
{
// Lookup employee information.
char szName[51];
if ( LoadEmployee( (unsigned long)nEmployeeSSN, szName ) )
{
// Create a new Employee object.
jclass clsEmployee = env->FindClass( "Beetle/Employee" );
jmethodID constructor = env->GetMethodID(
clsEmployee,
"<init>",
"(JLjava/lang/String;)V" );
jobject objEmployee = env->NewObject( clsEmployee, constructor,
(jlong)nEmployeeSSN,
(jobject)env->NewStringUTF(szName) );
// Map the new Employee object.
jmethodID mapEmployee = env->GetMethodID(
env->GetObjectClass(obj),
"mapEmployee",
"(JLBeetle/Employee;)V" );
env->CallVoidMethod( obj, mapEmployee,
(jlong)nEmployeeSSN,
objEmployee );
return objEmployee;
}
// Invalid SSN.
return NULL;
}
To create the new object, the native code must identify both the class and the constructor to be used. The FindClass function takes the fully qualified name of the class, using a forward slash to separate package and class names. The GetMethodID function takes class, and the name and signature of the method. (Please see Sidebar 2 for details on method signatures.) The NewObject function takes the class and method ID, as well as all constructor parameters. The constructor we’ve chosen to call takes a long integer and a string. We can’t just send a character pointer to Java code; we must first package it in a String object. Fortunately, the NewStringUTF function takes care of that for us.
We want to ensure that only one Employee object is created for each record in the database; to enforce that limit, we map all new Employee objects by their database keys. We write the code to handle the map in Java, so that we can take advantage of the Hashtable class. Our native code must therefore call a Java method on the current Company object. Again, we use GetMethodID to look up that method by class, name, and signature. This time, though, we use CallVoidMethod instead of NewObject because we are not calling a constructor; the object already exists. (Note that if the method returned a value, we would use a different function, such as CallIntMethod, CallFloatMethod, and CallObjectMethod.)
We have completed our first native method. Compile, set breakpoints, test, and celebrate. We’ve already experienced three different features of JNI: We have implemented a native method in C++ and called it from Java; we have created a Java object from C++; and we have invoked a Java method from C++. We’ve seen the central aspects of JNI, and we’ve only implemented one method! Now it’s time to take what we’ve learned, replicate the pattern (via clipboard code reuse), and implement the next few native methods.
Make things easy on yourself
After cruising along for a while, we feel pretty confident in our ability to write native methods. We’ve loaded employees, customers, invoices, and commissions — all with very similar code. But then we hit a snag; when a representative makes a sale, Aphid must create a new Beetle.TransactionInvoice object, populate its fields, and commit it to the database. That’s simple, right? Just write commit as a native method and extract the information from the object’s fields.
But it’s not that straightforward. The date is stored in a Date field, and we have to go through the GregorianCalendar class to gain access to the month, day, and year values. The code is simple enough to write in Java, but not in C++. We would have to use FindClass, NewObject, GetMethodID, and CallIntMethod repeatedly, creating a jumbled mess of unreadable code, which would become a maintenance nightmare.
Relax. If it’s easier to write something in Java, then write it in Java. Instead of implementing commit directly in native code, we can have it do all the footwork and then call a native method. In that case, we define the native method as follows:
native private static long createInvoice(
int nDay, int nMonth, int nYear, long nCustomerID, float fAmount );
In C++, we declare this:
extern "C"
{
_BEETLEJNI_EXPORT_ jlong JNICALL Java_Beetle_TransactionInvoice_createInvoice(
JNIEnv *env,
jclass cls,
jint nDay,
jint nMonth,
jint nYear,
jlong nCustomerID,
jfloat fAmount );
}
Notice that we made the native method static. Since we have gathered all the necessary information in our Java method, the native method doesn’t need access to the TransactionInvoice instance. The only impact that has on our C++ code is the second parameter; instead of getting a jobject, our native code gets a jclass. As it happens, we don’t even need that parameter because the body of the native method makes no JNI calls at all! We’ve taken a potentially hairy situation and turned it into our simplest native method yet.
Return a collection
We’re on the home stretch of our application development, and so far we’ve vaulted every hurdle. One last requirement stands in our way to the finish line. Naturally, the sales representatives are interested in the status of their commissions, and they would like to know when they will get paid. Beetle already generates a list of payable commissions for a report; we want to use that same business logic to display commission status in Aphid. Past experience has taught us that we can write most of the code in the Java method Beetle.Company.updateCommissionStatus. For a given employee, that method loops through all commissions and updates their status. To obtain the list of payable commissions, we define the following native method, static to the Beetle.Company class:
native private static long[] getCommissionsPayable( long nEmployeeSSN );
That is the first native method we’ve encountered that needs to work with an array. Arrays aren’t too problematic as long as you follow a few rules. In native code — just as in Java — arrays must be constructed before they are used. They must be given a size at construction time and cannot be resized afterward. To access the array’s elements, native code must first call Get<type>ArrayElements to obtain a pointer, then call Release<type>ArrayElements when it is finished with the pointer. The following native implementation obeys these rules:
_BEETLEJNI_EXPORT_ jlongArray JNICALL
Java_Beetle_Company_getCommissionsPayable(
JNIEnv *env,
jclass cls,
jlong nEmployeeSSN)
{
// Query for all unpaid commissions.
unsigned long *pCommissionID = NULL;
int nCount = GetCommissionsPayable(
(unsigned long)nEmployeeSSN, &pCommissionID );
// Allocate an array of longs.
jlongArray arrayID = env->NewLongArray( nCount );
jlong *pID = env->GetLongArrayElements( arrayID, NULL );
// Copy the data.
int nIndex;
for ( nIndex = 0; nIndex < nCount; nIndex++ )
{
pID[nIndex] = pCommissionID[nIndex];
}
// Unlock the arrays.
env->ReleaseLongArrayElements( arrayID, pID, 0 );
FreeCommissionsPayable( pCommissionID );
return arrayID;
}
Notice the call to FreeCommissionsPayable. That is a BeetleBL.dll function, not a JNI function. Because BeetleBL.dll allocates the array of commission IDs, it must also be the one to free the array.
Test the application
We’ve done it! The application is complete; the sales representatives are eager to start using Aphid; and we can tell the Oracle migration team that we’ve done half their work for them by separating the Beetle business logic. Let’s exercise the system to see what we’ve accomplished.
First, let’s recap our machine configuration. We have an Access database for which we’ve created an ODBC data source named BEETLE. We’ve built all of the C/C++ binaries into the devpath directory, which we have added to the path. Finally, we have built the Java binaries, the main one being AphidApp.class, into Javaclasses directory.
Now, let’s run Aphid. Launching it either from the Java IDE or by using javaw.exe, we see the main split-screen appear. On top, it lists all account activities for our test representative, Jill. At the bottom, it lists Jill’s commissions, and we see that the commission from her ABC sale is still payable. Now we launch Beetle by running BeetleUI.exe and let it process Jill’s payroll. Returning to Aphid, we choose Refresh from the File menu. (Automatic update, while entirely feasible, is also beyond the scope of this article.) The indicator shows that Jill’s commission is now paid.
Opening “Beetle.mdb” in Access, the Customer table shows that only ABC is a customer, because Jill is still working on her XYZ account. But let’s return to Aphid and suppose that Jill makes a sale. We choose New, Sale from the menu, enter a modest sale for ,000 to XYZ, and press OK. Now when we look at the Customer account, we see that XYZ has been added. Running the GL query, we can also see a ,000 invoice, a 00 commission, and no double entry — the accountants will be pleased!