Java Tip 117: Transfer binary data in an XML document
Three ways to encode and decode binary data for embedding within an XML document
XML has gained considerable popularity over the past few years as the solution to enterprise integration problems. It provides the means for exchanging data in a platform- and language-independent manner. To achieve this independence, XML exchanges encoding efficiency and network bandwidth for simplicity. Applications use XML documents as the universal datatype for passing data between one another without worrying about whether both applications use the same distributed object framework.
While incorporating XML into your distributed applications, you may encounter the need to transfer binary data as part of your XML document. For example, you may need to pass to the client binary images embedded within an XML document, which includes additional data elements such as images. Simply embedding the byte values within the stored XML document won’t work due to the XML specification’s valid-character restriction and due to character encoding and decoding as the document travels from its source to its parsing destination.
According to the XML 1.0 specification, valid character values include the following ranges of hexadecimal values: 0x9, 0xA, 0xD, 0x20-0xd7ff, 0xe000-0xfffd, and 0x10000-0x10ffff. The specification also uses the character definition specified by the ISO/IEC 10646 standard and requires that all conforming XML processors “…accept the UTF-8 and UTF-16 encodings of 10646.”
For readers not familiar with the ISO/IEC 10646, the standard was first published in 1993 by the International Organization for Standardization (ISO), whose objective specifies the encoding of characters used in every written language into binary form. To provide compatibility between the multilingual encodings and most existing software applications that use the ASCII standard, the ISO has defined many transformations including the UTF-8 and UTF-16 encodings. For more information about the ISO/IEC 10646 standard and UTF encodings, see the Resources section.
What does all this have to do with the problem at hand? Well, if you embed the binary data within the XML document within a specific element tag, the receiving XML processor attempts to interpret the byte sequence following the UTF-8 or UTF-16 encodings. This most likely causes the parser to encounter invalid sequences and fail.
This implies that you must encode your own binary data into the valid character set before embedding it into the XML document. Obviously, you then have to decode the data on the receiving side. In the rest of this tip, I describe three different approaches for encoding binary data before embedding it into an XML document.
The brute force approach
The direct approach to solving this encoding problem converts each binary data byte into its two character, hexadecimal representation. By doing that, you encode the 256 possible byte values using for each byte two characters from the character set 0-9, a-f:
byte[] buffer = readFile(filename);
int readBytes = buffer.length;
StringBuffer hexData = new StringBuffer();
for (int i=0; i < readBytes; i++) {
hexData.append(padHexString(Integer.toHexString(0xff & buffer[i])));
}
As the code above illustrates, the conversion is simple enough. Timing the conversion routine above on a typical desktop PC (a Pentium III machine running at 800MHz with 256MB of memory) gave my team a conversion rate of 485 KB/sec. Note, we used a StringBuffer rather than plain String concatenation to build the binary buffer’s resulting character representation. We did that to avoid the unnecessary cost of repeatedly creating and then releasing String class instances. If necessary, you could accelerate this conversion using a hexadecimal number lookup table as shown below. Timing the conversion on the same PC gave my team a conversion rate of 1,920 KB/sec using this approach — about a four-fold increase:
public final static String[] _hexLookupTable = { "00", "01", .. ,
"fe", "ff" };
for (int i=0; i < readBytes; i++) {
hexData.append(_hexLookupTable[0xff & buffer[i]]);
}
Although this approach lets you encode your binary data within the XML document, it wastes network bandwidth. For each byte in the original binary file, you now get two characters in the resulting XML document. For transferring large binary data sets, this is an important consideration.
Base-64 encoding approach
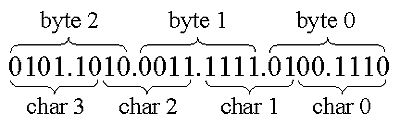
The next approach, in terms of encoding/decoding complexity, is the Base-64 conversion. Developers have used this approach for a long time to encode binary data within mail messages before transporting them through mail servers that allow relatively short lines of 7-bit data units. The encoding algorithm processes a byte stream in 3-byte sequences. Each 3-byte sequence parcels into four 6-bit data units as shown in the following figure.

Each 6-bit data unit then encodes into the character stream as the corresponding character from the character set: A-Z, a-z, 0-9, +, and /. You use the additional character = to pad the byte stream’s last one or two byte portions. RFC 2045 describes the algorithm in more detail.
The advantage of this approach is it encodes three data bytes using four characters resulting in an encoded document that is 33 percent larger than the original binary document. Compared to the previous approach, you generate 1.33 characters per byte instead of 2 characters per byte.
Another advantage is that it has been widely used for a long time and many implementations are available for free over the Internet. This tip uses the Apache SOAP 2.1 implementation in class org.apache.soap.encoding.soapenc.Base64. In terms of conversion performance, the approach is very fast since it consists of binary shift and table lookup operations. My team timed the conversion on the same PC and binary data set as the first approach and got a 2,050 KB/sec conversion rate. The resulting document looks like the example below:
<?xml version="1.0" ?>
<image name="music_inside.bmp">
<image-height>256</image-height>
<image-width>256</image-width>
<image-data>Qk1qjQ8AAAAEAAAo ... CAAAABAAAAAQAA+/</image-data>
</image>
In addition to the binary data, the XML document includes additional information about the image such as its name and its size.
Huffman coding approach
This last approach uses the binary data sets’ statistical properties to compress the resulting encoded character stream. The first approach encodes every binary value using two characters from a printable character set. In that case, the average code length is fixed at two characters per byte. For many data sets, if you construct a histogram of each byte value’s occurrence frequency within the data set, you get a very uneven distribution, where some bytes are used very frequently while others rarely or not at all.
Huffman coding uses this statistical property to reduce the average code length. You represent the most frequently used bytes using single characters or short character sequences, and the least frequently used with longer character sequences. For cases where the distribution is highly skewed towards a byte value subset, this encoding approach is very effective; it’s not as effective for cases where the distribution is fairly uniform.
This approach’s average code length and the data distribution within the encoded data set are related to one another through the data’s mathematical property called the entropy. For more information about entropy, the Huffman coding algorithm, and the algorithm’s optimality, refer to Elements of Information Theory in Resources.
My team implemented our simple Huffman encoder as follows. We needed to encode 256 distinct values using our self-imposed two-character sequence maximum; therefore, we defined the following character-sequence set. The ranges A-Z, a-z, 0-9, +, and / form the base set of 64 single-character codes. We then added an additional 192 two-character codes by preceding each code from the 64 base set with the characters :, ;, and -. This formed the coding table of 256 possible codes as the code below illustrates:
public final static String[] _codeBook = {
"A","B",..,"Z","a",..,"z","0",.."9","+","/",
":A",":B",..,":Z",":a",..,":z",":0",..":9",":+",":/",
";A",";B",..,";Z",";a",..,";z",";0",..";9",";+",";/",
"-A","-B",..,"-Z","-a",..,"-z","-0",.."-9","-+","-/"};
Notice we used additional characters to form the prefixes of the two-character codes. This results in a prefix code. The benefit of using a prefix code is you can decode the resulting character stream in one scan through the data.
The next step maps each code to a byte value based on the byte value’s occurrence frequency within the data set. You can do this in two ways. For fairly large documents, it is more efficient to calculate each byte value’s occurrence frequency by analyzing a subset of the possible data sets. You then map the byte values to a character from the code table based on their frequency; mapping remains fixed after that. This works well when most transferable data sets share similar statistical properties.
For extremely large binary data sets, where encoding efficiency is most critical, you can calculate the mapping for each binary data stream before encoding. This requires that you also transfer the map within the XML document so the receiver knows how to decode the received data. When the binary stream is very large, the overhead of adding 448 bytes (the code above in the sequence corresponding to byte values 0, 1, … 255) to define the mapping is negligible.
My team implemented the encoder using the first approach. In that approach, once the mapping is defined, it is then fixed. The encoding process then requires simply looking up each byte value in a map, converting it to a String, and appending the String to the end of the character stream. We tested the implementation on the same binary document and PC as in the previous two cases and attained a 3,640 KB/sec conversion rate. We computed the average code length for this particular binary document to 1.0002 characters/byte, making the resulting encoded document almost equal in size to the original binary document.
Of course, the average code length depends, as I mentioned earlier, on the statistical properties of the binary data we encode. The best case would give you a one-character/byte average code length. This corresponds to the case where the binary data includes a small subset of the 256-byte values you can encode using single character code. The worst case would be a document that includes an equal number of each 256-byte value (a uniform distribution). In this case, you would use all code an equal number of times, giving you an average code length of 1.75 ((64*1 + 192*2)/256) characters per byte.
Try it out!
In Resources, you’ll find the source file, ProcessingImage.java, and the sample binary data file used to benchmark the performance of each coding style. Try this out on your own data files and other algorithms to get a deeper feel for the tradeoffs.
The best candidate
This tip discussed three different approaches for encoding binary data for inclusion into an XML document. The approaches ranged from the straight-forward encoding of using each byte value’s hexadecimal values to the most sophisticated approach of Huffman coding, which uses the binary data’s statistical properties to reduce the average code length. In summary, for cases where the transferable data sets are very large and where the byte value distribution within the data set is skewed, the Huffman coding approach is the best candidate. For cases where the data sets are not large and you need a quick implementation, the Base-64 encoding scheme is the best choice.
JavaWorld’s Java tips coordinator John Mitchell also proposes another experiment. You can use zip compression on the resulting XML document from any encoding scheme before transferring the document. This is an option when the development team builds both the XML document’s receiving and transmitting sides. Compression tends to be a CPU-intensive operation but it can reduce the document size considerably. On the other hand, Java has built-in classes for zip encoding and decoding so it’s easy to implement.




