Frameworks save the day
Use an extensible, vendor-independent framework to accomplish the top tasks in server-side development
In server-side development, a number of core tasks crop up over and over again. Most developers know that such tasks can and should be pulled into a core framework, built and tested once, and reused across multiple projects. However, knowing something and doing it are two different things.
The framework concept has been kicking around in software development for a long time in one form or another. In its simplest form, a framework is simply a body of tried and tested code that is reused in multiple software development projects. Smart companies invest formally in frameworks and good developers build up a library of components that they use often. Such actions reduce development time while improving delivered software quality — which means that developers can spend more time concentrating on the business-specific problem at hand rather than on the plumbing code behind it. A good framework also enhances the maintainability of software through API consistency, comprehensive documentation, and thorough testing.
At one level, the framework showcased in this article does the simple things you need every day: logging, exception handling, JNDI lookup, configuration, and database management. Delving deeper into the design and implementation however, you will see that the framework also provides application server independence, future hooks for adding management services, and a well-defined extension mechanism.
Note: To download the framework’s complete source code in zip format, go to the Resources section below.
Goals for the framework
Before setting out to build the framework, it’s worthwhile to set out some basic objectives against which we can measure success:
- The framework should be simple. The number of objects should be minimal, with simple methods and shallow inheritance hierarchies. Furthermore, the API must be consistent across different framework modules to minimize the ramp-up time required to start effectively using the framework.
- A developer should be able to add new services to the framework easily. You can be sure that your framework will grow over time, becoming a balkanized hodge-podge reflecting the designers’ and developers’ personal coding styles. If from the start you lay down a well-defined extension mechanism that is powerful enough to meet the needs of your framework providers, you’ve laid a sound base on which to build and extend the framework over time.
- The framework should have solid documentation. This may sound obvious, but it rarely happens in practice. At the very least, users will expect a good level of javadoc commenting and an overall block diagram outlining the major components in the system, along with sample code showing how the components can be used.
- The framework should be usable from any J2EE component. This includes EJBs, servlets, JMS listeners, and regular Java classes. Accomplishing this is not difficult, but it needs to be kept in mind during development.
- Developers should be able to deploy the framework to multiple application servers. A really useful framework will offer developers the same level of functionality no matter what application server they work on. For example, if a vendor claims that its environment is EJB 1.1 compliant, then I expect certain things to be present in that environment. In the same way, if a framework is available on application server X, then it should be fully functional on that server, no ifs or buts. Above all, this complexity should be hidden from the end user wherever possible.
Framework assumptions
In order to make our framework easier to maintain, some assumptions are made:
- Supported databases: The only component that uses a database directly is the
DbConnectionService. Any database that has a JDBC driver will work. - Supported JDK versions: 1.2.2 or higher. JDK 1.1.x is explicitly not supported. JDK 1.3-specific APIs are not used, as the 1.3 JDK has still not gained widespread acceptance as a production VM.
- Target application servers: BEA WebLogic 5.1 and jBoss. This point is not so much a restriction, more a declaration of what comes working (and tested) out of the box. There is no reason why the framework couldn’t be extended to other application servers as required (in fact, it is designed in such a way to make this as clear and easy as possible).
- Vendor-specific functionality: Vendor-specific functionality would clash with the stated goal of providing a vendor-independent framework. Though in some cases vendors have added proprietary extensions to their product that would enhance performance or flexibility, such extensions have been eschewed here in favor of complete vendor independence.
The framework’s five basic components
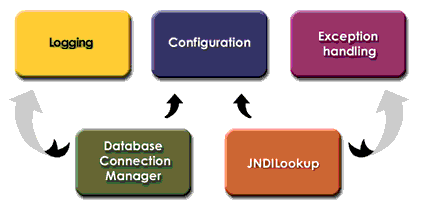
Next, we look at the five core components — logging, JNDILookup, configuration, database connection management, and exception handling — that make up the framework. These are the hosted services that can be leveraged by business-specific code, as seen in Figure 1.

Logging
Logging represents the framework’s single most important component. Apart from the value it adds to users, it is crucial to debugging the framework itself. Put simply, a system without a logging component and an accompanying set of logging guidelines built into the coding standards will take a long time to develop (and debug) and will be very difficult to maintain.
So what are the requirements for logging?
- Simplicity: A logging component must be simple to use, or developers won’t use it. Instead, they’ll use
System.out.println, thus impairing performance. With that in mind, only one import statement and one line should be necessary to use the logging service, no more. - Flexible output formatting: Systems regularly go live without any reporting features built in. It typically isn’t critical to the main system functionality to have things like usage patterns, audit trails, and so on reported; such features are thus instead penciled in for phase two or even phase three releases. Though you may not think you need this functionality now, wouldn’t it would help a lot if your plain old logging module could handle it already? Most third-party reporting tools can read your output logs as long as they are structured — the logging service should be able to handle this in a configurable way.
- Support for output to different channels: In development, piping output to
stdoutas well as a file is helpful; in production, this should be turned off to improve performance.
The design and construction of a logging service could take up a complete article in itself. Instead of spending time building one, I have picked one off the shelf that I consider to be best of the breed: log4j (see Resources for more details). Although most vendors (including jBoss and WebLogic) provide a logging service as part of their products, their services aren’t used here because they would affect the cross-platform portability of the framework.
In the framework lifecycle, two incarnations of the LogService exist. Initially, the FrameworkManager and the logging service itself use the BootLogger, as neither component can assume that the fully-fledged logging service has been located and bootstrapped. Once the main logging service has been initialized, the other framework components use it in preference to the BootLogger, which possesses a subset of the main service’s functionality.
Finding objects/references stored on a JNDI tree
Next, let’s look at the JNDILookup component. JNDI trees serve as the telephone directories of the enterprise Java world. Looking for that hot new bean in town or the latest connection pool? You will find them in the JNDI environment as named and configured by the application assembler/deployer. The framework provides a window into this world that hides the vendor- and location-specific details from developers when they don’t need to or want to be aware of them. This service also serves as an example of how to use the framework’s ability to detect the current application server to configure a client service appropriately. See the JNDIService javadoc for more details on this functionality.
Using a configuration lookup to avoid hardcoding variables
Our third component is the configuration lookup. Although EJBs can use the java:comp/env JNDI context to store information that should live outside the codebase, this is not so easy to do for non-EJB components. With the ConfigService, all J2EE components can retrieve values from a central file-based repository. Thus, you won’t have to hardwire these values or use J2EE component-specific mechanisms.
Database connection pooling
We next turn our attention to the framework’s fourth component, the database connection manager. Databases are a commodity in the enterprise Java world. Most of the time, developers don’t need or want to know where a database is; they simply want a connection to talk to it. As the relational world becomes more in tune with the object world, eventually a service like this will filter completely behind the scenes; knowing that your objects are persisted to a database would be like knowing where a spool file for email lives on a server — you don’t care, you just want to use email. Until that happy day, however, we need a database-connection finder service.
Exception handling
A consistent exception handling strategy is a core requirement for any distributed system. Put simply, each framework components should be honest in all its dealings. In other words, if I ask the JNDILookup to find a bean for me, I don’t want to get a null reference in return! In a better world, the framework would either return a valid object or explicitly inform the caller that the service was unable to fulfill its request. Indeed, the framework provides a base exception class that developers can use to follow this rule consistently. If you choose not to follow this rule, your reasons why should be clearly outlined and well documented. Also, the JNDILookup service is provided as an example of how to subclass the base exception and use it in the public API.
Now that the individual components have been detailed, we turn our attention to the larger strategy of framework configuration and management.
The framework brain
Let’s recap the progress to date. So far, we’ve built up the five core modules in the base framework. Where do we go from here? What doesn’t the framework do that it should? Well, it can’t handle a hybridized deployment environment yet — it can’t morph to suit the system it finds itself in. Also, as we add new services, how will the framework know about them? Can we add some brains without killing performance? The answer is yes! (For what follows, I presume you understand design patterns along with their advantages and disadvantages; if not, see Resources for a good link).
In the following sections, we’ll first examine the main “command and control” component — the FrameworkManager. Next, we’ll look at the mechanism used to interrogate the framework host, and examine our deployment strategy for the framework. Finally, we’ll touch briefly on the process used to build the framework.
The framework factory/manager
Figure 2 shows the clear separation of responsibilities promoted by the framework. Because of the well-defined extension mechanism and FrameworkManager, business-specific code does not need to initialize a framework service before using it. The business-specific code is also completely unaware of the specifics in configuring the framework to the current host environment. Indeed, at the business-specific layer, only the service’s public APIs are visible.

In addition to the usual factory tasks of component creation/initialization and location, the FrameworkManager figures out what application server it has been deployed to and makes that information available to its client components. As it boasts more intelligence than a regular factory, it’s called FrameworkManager rather than FrameworkFactory.
I used Ant (a Java-based build automation tool that removes many of the pitfalls associated with building large Java codebases; see Resources for more information) to build the framework. I’ve also taken advantage of a very powerful Ant Task in the framework itself, the MatchingTask. This class searches a specified directory structure for files that meet a predefined filter pattern; such functionality plays a key role in the autodiscovery of framework components.
Another paradigm used is the service provider interface (SPI). In the context of the framework, the SPI approach differentiates framework users into two groups: developers who want to use the framework, and developers who want to port or extend the framework. Members of the first group concern themselves only with the public interface, while those in the second are primarily interested in the underlying implementation — the guts of the framework itself. The schematic above illustrates how the SPI and the public API relate to one another. Framework users don’t care about the SPI; it affects their code only in that they see a consistency in the naming and location of framework services, since the SPI imposes this on the service providers. Framework providers, on the other hand, care a lot about the SPI, since it acts as a blueprint for the skeleton of any service added to the framework. The SPI defines how a service is named, configured, initialized, and made ready for use.
So how do you write a new service that plugs into the framework? Well, you simply need to conform to the SPI requirements:
- Your service must extend
framework.manager.FrameworkComponent. Also, in order for your service to be automagically found, it must be placed in or under the root framework package (specified by the System propertyframework.rootdir). - You must provide a properties file in the framework configuration directory that contains the properties your service requires for successful initialization. The file must be named
<<service class name>>.properties. For example, the properties file for the JNDIService is calledjndiservice.properties. The System propertyframework.configdirspecifies the location of the configuration directory. - That’s it! The framework management components take care of the rest. They will find and initialize your component, leaving it at the disposal of your waiting users.
Some tips:
- Watch the output to make sure your service was found and initialized successfully — make use of the
LogServiceto add messages to your service so you can see its progress. - Take a look at the example services provided (JNDI, Config, and DbConnection) to get a jump start on building your own service and adding it to the framework.
Addressing vendor portability
The key to transparently deploying the framework to different application servers: vendors must set up System properties for their own use. The FrameworkManager inspects these properties to figure out where it has ended up and makes this information available to the components. Under this scheme, the component itself holds responsibility for per-component, vendor-specific initialization. A component should configure itself to its deployment environment. The FrameworkManager simply provides the component with the information it needs to do so. Some application servers provide hooks to execute start-up classes that could be used to initialize the framework. Unfortunately, this functionality is not part of any J2EE specification, so the framework cannot assume that it will be on all potential hosts. To solve this problem, a two-pronged approach is adopted. Where initialization functionality is provided, a regular start-up class can be used (WebLogic has this functionality and a sample start-up class is provided as part of the framework). See the javadoc for framework.manager.WLStartUp for more information on how to set this class up. Where this functionality is not available, the framework employs lazy initialization instead. jBoss provides similar start-up functionality through its implementation of the JMX specification, but I chose not to use this in order to show the lazy-loading feature of the framework. Because logging has a special status as the first service initialized, and because all services use it, I chose it to perform the check of first bootstrapping the FrameworkManager to initialize itself.
Deploy the framework to development/production
Now that we’ve solved the question of how to autoinitialize the framework, what is the best way to physically deploy it to the application server? JDK 1.2 conveniently provides the hooks for this. The addition of a $JAVA_HOME/ext directory that is autoinspected by the Java runtime gives us an easy way to make sure that the framework is located in a consistent location across application servers; this also means that the framework is added to the classpath automatically. Developers need only import the classes they require to start using the framework. If you are a little cagey about third-party classes being automatically added to your production classpath, then simply add the directory in which you built the framework to your application server classpath.
Building the framework
Like practically every other Java project out there, the framework is built using Ant. I won’t go into Ant in detail here; suffice it to say that Ant is great and that you should be using it. If you’re not, check out Resources to find the project homepage. The required build.xml is supplied as part of the jar file. Remember, Ant isn’t just used to build the framework; it also supplies some of the internal framework functionality, so you must have it in order to run the code.
Put it all together
Now that we’ve looked at the background, let’s turn to using it. In the supplied jar file (see Resources), you will find TesterBean, a regular stateless session bean with an insatiable desire to — yes you’ve guessed it — read configuration files, log data, and chew up sequences as fast as possible. The bean should give you a good idea as to how the framework can be used in EJB development, but the code equally applies to servlets or any other server-side component type.
How to use the framework
For your project, the framework should be regarded as almost another Java package. In much the same way as you go into a Java runtime and expect to find java.util.HashMap or java.lang.Thread, you will expect to find logging, config, JNDILookup, and so on there too. By having these services to rely on, you will spend less time on writing the plumbing for your code and more time on implementing the actual business logic of your application.
Future extensions
The framework is complete as is, in that the requirements laid out at the beginning of the article have been met. However, a number of potential enhancements are already obvious. You could:
- Port the framework itself to more application servers. To give coverage to both the commercial and open source worlds, I picked the most popular commercial and open source application servers (in my opinion) as the initial targets. Extension to other application servers, therefore, seems like a worthwhile endeavor.
- Extend the
ConfigServiceto use XML to retrieve arbitrarily complex (read-nested) objects from cold storage. JDOM is the obvious candidate here because it offers a simple Java representation of an XML Document. - Extend the database connection pooling to retrieve a connection from a named pool or database. Accomplish this by overloading the
getConnectionmethod to take aStringas argument to facilitate applications that connect to particular database instances depending on custom business logic. - Target a couple of outstanding candidates ripe for frameworking. The most prominent of these is a JavaMail and unique id generator service (for surrogate keys), but there are plenty of others too.
- Modify the framework test harness to use jUnit. jUnit stems from the extreme programming paradigm, which has a lot of valuable insights into methods for testing software (basically making testing part of development). Also, jUnit is fast becoming a standard used to test Java software. In fact, there is a custom task supplied as part of Ant which allows you to fire up a test sequence as part of your build process — very handy.
Pitfalls in extending any framework
Within the enterprise Java community, there is a wealth of resources available for the types of core components that any basic framework needs in a first iteration. There are also many production-grade libraries available that you can pull together into a de facto open source COTS (custom off the shelf) environment. With these resources, you should be able to quickly achieve the level of functionality you need for your projects.
Once you have built up this core library, you will immediately start to see more and more items in your applications that can be approached in the same way. Doing this can add tremendous value to your application but can also be a waste of time if not approached correctly. Let’s examine why.
Any first framework iteration cannot help but be successful. Every system, no matter what the business application, needs things such as logging, configuration, database JNDI connectivity, and an exception handling strategy. However, once you move beyond this plumbing into the business-specific layer, your chances for success greatly diminish. This might sound pessimistic, but here’s the problem you face in a nutshell:
The more your framework does, the less reusable it is.
Let’s say your company operates in the financial trading sector, and you decide to expand the framework to tackle the ways in which stock trades will be modeled, handled, stored, and assigned to users. Designing and implementing such a framework so that it is generic enough to be reused across different business scenarios proves a difficult task. Further, it is difficult to get the same return on investment at this level, as opposed to the plumbing or first iteration level. I’m not saying it’s impossible, but I think that the reason frameworks have gotten some bad press in the last five to ten years is that their creators tried to do too much and failed. It’s better to set clear limits on what is definitely framework territory and what is business-specific, and always be very, very wary of moving that line. Here are some rules of thumb you should apply to deciding whether something should be built as a reusable component or not:
-
What are the estimated net number of developer days saved by your component? This figure should take into account the extra time it takes to build a service that it is truly reusable, with the extra level of documentation required (there’s a big difference between rolling a service out to one project, in which it will be used by the same people who wrote it, and deploying it across multiple projects, where there may be no original authors on the team). To calculate the number of saved days, a simple formula to use is:
n = (p * pc) - (tfc + (p * s))Where:
- n = Net number of developer days saved. If this is a negative number, you’re not looking so good!
- p = Number of estimated projects that will use the new generic component.
- pc = Project cost (in developer days) to develop the component in a way specific to that project. This will be less — potentially much less — than the time required to come up with a generic component to do the same job.
- tfc = Total framework cost (in developer days) to develop a generic, reusable component. This figure should account for the increased time and effort needed to gather requirements, do the design, implement the framework, document it, and roll it out.
- s = Required framework commitment to support the component per client project (in developer days).
The formula shows that you win the numbers game only if you can build the generic component in a reasonable time and maximize its reuse. In other words, you should seed the framework team with your best developers and gather the cross-project service requirements in a rigorous fashion before starting to build.
- How complex does the design have to be to accommodate all future scenarios? Put another way, will the component require far more design and implementation time to meet requirements that are not part of the current project? If so, then you need to be doubly sure that you will regain this time with interest with the component’s reuse.
- Are the business processes you are modeling static or dynamic? If they are static, then it’s a good idea to find reusable pieces. If they are changeable, consider a different approach, such as investing in a rules-based engine that integrates with your environment (that is, buy instead of build).
Conclusion
Now let’s review how we’ve done.
Measuring success
Let’s examine our stated requirements from the beginning of this article and see how well the framework addressed them:
- The framework should be simple. The public API of the framework is as simple as possible while still offering a base level of functionality to the end user.
- Developers should be able to add new services to the framework easily. By providing the framework SPI, developers can add their own custom services quickly (and correctly) while relying on the
FrameworkManagerandFrameworkComponentclasses to handle initialization and configuration. - The framework should have solid documentation. This point is open to opinion! Documentation can always be improved; but, by reading this article in conjunction with the javadocs, developers should be able to use and understand the current framework without having to browse the source code. With the included test EJB, the developer can also see how the services are used.
- The framework should be usable from any J2EE component. The underlying framework implementation makes no use of features specific to one particular J2EE tier, so it can be used in any J2EE component.
- Developers should be able to deploy the framework to multiple application servers. The framework codebase has been tested on two application servers, one commercial and one open source, and should run on any application server without code modification (although the per-service properties file will need to be updated). By not using proprietary features, cross-application server portability is maintained.
What about Avalon?
When I began researching this article, I ran across Avalon pretty early on. It’s a framework project under the Java Apache umbrella that aims to “create, design, develop, and maintain a common framework for server applications written using the Java language.” Avalon will be a very powerful framework once it matures, and its scope goes far beyond anything considered here. However, I don’t think it’s ready for prime time, so I didn’t cover it in the article. It’s definitely one to watch, though.
Wrap it up
This article has showcased a framework that autodiscovers and deploys its constituent components, while also supporting the configuration of those components to suit different vendor environments. In addition to detailing the design and construction of an extension strategy, this article includes example services to show how the framework can be extended in a clear and consistent fashion. Wherever possible, the codebase leveraged best-of-breed, open source packages such as Ant and log4j. I hope that, having read this article and downloaded the source code, you will agree that using the framework will make developers’ lives easier in the enterprise Java world and improve code quality and maintainability.